主要遇到两个问题,比较有通用性,记录一下:
1. -lpthread 修改为 -pthread
2. -ldl 修改为 -Wl,--no-as-needed -ldl
在linux编译遇到
undefined reference to pthread_mutexattr_init undefined reference to dlopen
可能跟这两个问题相关。
主要遇到两个问题,比较有通用性,记录一下:
1. -lpthread 修改为 -pthread
2. -ldl 修改为 -Wl,--no-as-needed -ldl
在linux编译遇到
undefined reference to pthread_mutexattr_init undefined reference to dlopen
可能跟这两个问题相关。
很长一段时间都没有鼓捣重装系统了。前些日子旧笔记本坏了,买不起MBP的咱只好入手了一台惠普的win8系统的本本。
近来需要一个linux环境进行线下测试,这台本本就成了实验对象。本以为装个linux还不简单么,装个ubuntu分分钟搞定的事情,没想到居然屡遭挫折。最简单的方法就是通过easybcd软件进行硬盘安装了。然后遇到的第一个难题就是怎么重启机器。win8新的电源管理模式,所谓关机其实只是打瞌睡。网上查到在控制面板-电源管理中可以关闭这个功能。OK,重启。进入引导界面却引导失败,提示找不到文件。这个问题纠结了很久,我以为是自己填写的磁盘号错了,通过存储管理可以看到除了系统可见的C盘D盘E盘外,还有好几个分区,此时我还没了解到这是GPT分区表的特征,从(hd0,0)到(hd0,5)试了个遍,通通无效。
经过这么多纠结我终于决定放弃硬盘安装,转而采取刻录光盘安装,还好新本本光驱还没坏(不得不吐槽下本本光驱的脆弱身板。。)。结果再次挫折。。光驱引导界面进去之后无法进入到liveCD的试用模式,也无法直接安装,于是使用检测光盘那个选项吧,统统黑屏,进去光盘也不转。试用模式的最后会输出两行字,说是无法从cd0的某扇区读取数据。莫非是烧CD烧坏了?于是再烧一张,并且烧写结束的检测光盘步骤也检测正确了,ubuntu的iso检测checksum也检测正确了,应该没问题了吧,用新盘重试,还是一样的问题,甚至提示错误的扇区编号都是一样的,我看着状况应该不是烧写的问题。
只好再度重启去BIOS看看了(其实应当是叫做EFI,这个时候我还没意识到这个问题)。发现boot option中有一个选项是开启legacy support模式。注解中说这个模式用于引导win7及以前版本,推荐不要开启可能会导致(win8)系统无法引导。我晕,估计问题就出在这了。首先先不管一层层的警告先把这个选项开了,然后我也注意到这说明这台机器的引导方式已经与以往不同了,以往的引导方式已经是legacy了。。
重启之后还有提示,说有延迟的修改,不顾各种警告允许修改生效,再次通过liveCD引导,终于可以进入熟悉的ubuntu试用界面了。不管那么多进入安装。根据ubuntu以往的尿性,应该是对windows超级友好兼容,不用担心引导项问题的(我还是没意识到EFI这个问题的严重性)。结果装好发现就是败在这个疏忽上了,grub没有正确地安装,还是直接进入到windows引导界面了。
不过这时候已经知道病因了,那么在网上求医问药就比较顺当,找到了许多文章,介绍了许多不同的解决办法。我采取的是这篇文章中介绍的办法,通过liveCD进入ubuntu后,挂载sda2,这是gpt的引导分区。其文件夹结构为
<DIR> Boot
<DIR> HP
<DIR> Microsoft
<DIR> Ubuntu
其中Boot文件夹中有Bootx64.efi文件,Microsoft/Boot文件夹下有Bootmgfw.efi文件,Ubuntu文件夹下有grubx64.efi文件。可以看出Ubuntu安装程序已经安装了Ubuntu的引导文件,可是EFI系统没有识别出新的引导项,依旧直接启动了windows的引导文件。由于对EFI也是昨天折腾这个事才刚从网上了解,我还说不出所以然,为什么Ubuntu的安装程序无法正确替换windows引导文件,并且事实上ubuntu自动生成的windows引导项也是错的无法启动windows。应该说是新设备加上新系统吧,兼容工作不可能那么快跟得上。
网上提供的另一种解决方案是将linux引导信息写到U盘,通过U盘启动linux,这样做就避免修改windows的引导文件,应该说是方便企业级客户吧。这个方案来自linuxsir.org。可是对我来说太麻烦,不想采用。于是还是使用了上面引用的方案,将Ubuntu引导文件强行替换windows的引导文件,并将ubuntu的grub中增加一个项目,指向原来的windows引导文件(备份更名),从而解决问题。不得不佩服下这个方案的作者,这样强行替换引导文件确实是需要足够的知识和勇气的。。。
这里说明一下,我的系统引导文件分区与文章中一样是sda2,但可能不同系统不同,可以分别挂载查看一下目录结构就能确定具体是哪个。
好吧,长篇的唠叨说完,总结一下要点:
后记
总结完才意识到可能由于我没有关闭secure boot才导致ubuntu引导项安装失败以及easybcd设置启动项失败。由于昨天经历漫长的战役已经重启笔记本30次以上消耗了一整天的时间,暂时没有心情去继续研究了。附上似乎是比较官方的介绍easybcd双启动linux和win8的文章供参考。
how to dual boot windows 8 and linux
最后是参考来源:
最近用python写一个简单的爬虫,在模拟网站登录时遇到问题,就是登录后紧跟着302重定向,这时候cookie获取没做好,就会登录失败。
网上找了很多文章,可能是因为python版本不同之类的原因吧,很多方法试了都没用。这里踏破铁鞋找到了可用的方案,记录一下,希望能帮到后来的朋友。
鉴于python的版本浆糊问题,这里声明下,我使用的python版本2.7.3,并且使用的是urllib2库。
解决这个问题,其实说起来很简单,就是要自己定义一个RedirectHandler,在创建opener的时候作为参数放进去。
cj = cookielib.LWPCookieJar()
opener = urllib2.build_opener(MyRedirectHandler,
urllib2.HTTPCookieProcessor(cj))
这里我还要记录cookie信息因此还使用了cookiejar。
现在难点就在于这个RedirectHandler如何重写了。
urllib2.HTTPRedirectHandler.http_error_302(self, req, fp,
code, msg, headers)
通过这样一句调用,默认的redirectHandler已经支持在发现302头部的时候自动跳转到新的location去。但问题是返回的response中缺少了前一个请求返回的cookie信息。因此重点是如何在redirect handle中把前一个请求的cookie设置到新的请求中去。
class MyRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_302(self, req, fp, code, msg, headers):
setcookie = str(headers["Set-Cookie"])
cookieTokens = ["Domain","Expires", "Path", "Max-Age"]
tokens = setcookie.split(";")
for cookie in tokens:
cookie = cookie.strip()
if cookie.startswith("Expires="):
cookies = cookie.split(",", 2)
if len(cookies) > 2:
cookie = cookies[2]
cookie = cookie.strip()
else :
cookies = cookie.split(",", 1)
if len(cookies) > 1:
cookie = cookies[1]
cookie = cookie.strip()
namevalue = cookie.split("=", 1)
if len(namevalue) > 1:
name = namevalue[0]
value = namevalue[1]
if name not in cookieTokens:
cookiemap[name] = value
newcookie = cookiestring(cookiemap)
req.add_header("Cookie", newcookie)
return urllib2.HTTPRedirectHandler.http_error_302(
self, req, fp, code, msg, headers)
这里我处理cookie使用了比较土的方法手动解析的,各位如果有更好的方法也请不吝赐教。
重点其实就是那一句req.add_header(“Cookie”, newcookie),这里是从set-cookie中解析出cookie串后拼接成请求头填入req中,在接下来的一句调用默认handle的函数时请求头就会附有新的cookie信息了。
如此处理后的请求,返回后即可从response中读取出cookie信息
response = opener.open(request)
cookies = cj.make_cookies(response, request)
从三月份开始看Real World Haskell这本书,断断续续看到7月份,总算初步对Haskell有了一些认识。
我想,学习Haskell这门语言,第一个门槛就是Monad这个概念。今天初步来做一点总结。
在读书和试着用haskell做一些习题的时候,就会感觉到,haskell是一门实践性极强的语言。当然,他同时也是一门理论性极强的语言,他允许甚至鼓励你用数学方法去推导函数签名,通过定义一系列公理可以对特定类型的函数式进行数学变形,以达到最短最优美的代码形式。
但对于我而言,那些过分抽象的函数和概念,非常难以理解,并且即使是形式上理解了他的定义,还是无法理解他为何要如此定义,有什么意义。Haskell代码的特点在于极端的精炼,许多函数定义看上去什么都没做,像是在说废话。幸好RWH是一本非常好的教材,他通过许多实例来说明这些抽象定义在实践中的用途,让你看到许许多多在实际代码中经常遇到的痛点,在Haskell中都有解药。如同醍醐灌顶般爽快。(请参见代码交叉拷贝悖论)
Monad就是Haskell的一个经典设计。它来源于“范畴论”,可以说是数学中的数学,一坨“抽象废话”。我先不去考虑他的数学含义,单看他在代码中如何化繁为简。这里我抄一段RWH中的代码(略简化)。
data MovieReview = MovieReview {
revTitle :: String
, revUser :: String
, revReview :: String
}
simpleReview :: [(String, String)] -> Maybe MovieReview
simpleReview alist =
case lookup "title" alist of
Just title@(_:_) ->
case lookup "user" alist of
Just user@(_:_) ->
case lookup "review" alist of
Just review@(_:_) ->
Just (MovieReview title user review)
_ -> Nothing -- no review
_ -> Nothing -- no user
_ -> Nothing -- no title
这一段代码是说,有一个电影影评的类型MovieReview,包含revTitle,revUser,revReview三个字段。现在用一个association list来对他进行初始化,simpleReview函数中的case语句略似if else,我们可以看到这段代码的大意是说如果alist中含有title、user、review三个键值并且对应的字段不为空,则用这三个字段初始化MoviewReview类型,否则依次返回Nothing (Maybe是一个包装类型,它的值可以是对应类型的值,或者是Nothing)。
这里是采取了最传统的方式,展现了写代码时经常遇到的苦恼。三层if判断,里面的操作很雷同,应该有办法抽象出来。在C语言中我会采取的办法是把title, user, review三个键值存在数组里,并且通过一个循环来依次判断,虽然实现了重用代码,但是代码可读性变差了。代码主体内充满了类似
auto moviereview = new MovieReview (alist[keylist[0]],
alist[keylist[1]],
alist[keylist[2]]);
这样的代码。我们来看看Haskell如何通过monad实现对这样的代码的抽象。实际上Maybe类型就是一个Monad。一个Monad可以简单理解为一个包装类型,他包装了一个变量(可能是函数、操作、状态等等),并且提供一个“>>=”运算,这个运算的意思是,把它包装的变量提取出来,当作参数传入一个可以接受这种类型参数的函数中,而这个函数的返回值必须也是monad包装的。
另外Monad还需提供一个return函数,方便其他函数将原始类型包装为Monad类型。
class Monad m where -- chain (>>=) :: m a->(a -> m b) -> m b -- inject return :: a -> m a
为何要这样定义>>=运算,一个monad >>=运算将一个Monad (m a)中的变量(a)扔进一个(a -> m b)函数中,生成一个新的Monad,它包含的变量类型跟传入的可能不同(m b)。这个m b还是Monad,就又可以继续通过>>=方法扔进新的(a -> m b)中。并且这里特别将输入类型m a和输出类型m b分别表示,从而可以将许多不同的方法通过>>=连接起来。就好象一个Monad被送上了生产线,经过一道道工序加工它本身的类型也可以经过许多变化,最终输出一个m b。
这个定义非常优美,我相信c++中的输入输出流操作符就是从这里借鉴的。不过这个流可不仅仅能做输入输出的操作,它可以控制任何一种操作流,非常神奇。因此在RWH中称>>=算符是一种可编程的分号 每个操作后面用>>=结尾可以对应于命令式语言中的;分号,在haskell这样的函数式语言中,通过monad实现了命令式的编程范式。更加强大的是,他的可扩展性远高于传统的命令依次执行,具有灵活的可操控性。
Maybe就是一种monad。他的>>=方法将其包装的变量提取出来,给后续的函数作为参数。如果为Nothing则短路,直接返回Nothing
(>>=) :: Maybe a ->(a -> Maybe b) -> Maybe b Nothing >>= _ = Nothing Just v >>= f = f v
通过这一层包装可以很好的将前面的一段代码简化,依次处理title, user, review三个字段,通过>>=这个“可编程的分号”来控制操作流。如果任何一个字段出现Nothing,则后续的>>=函数都会返回Nothing,不会继续调用lookup函数。
simpleReview alist = lookup "title" alist >>= \title -> lookup "user" alist >>= \user -> lookup "review" alist >>= \review -> Just (MovieReview title user review)
可以看到代码已经充分简化了。但Haskell的设计者还是不满意,这样的代码还有重复之罪。如果我们可以直接将(lookup “string” alist)作为参数,放进MovieReview的构造函数的话,就可以一行代码实现这个任务了。现在遇到的困难是,lookup返回包裹在Maybe中的量:可能找得到,可能找不到。而MovieReview的构造函数,仅当三个查找都不为空的时候才应当调用,并且其参数应当是解除包装的字符串类型。如何将Monad包裹的值当作参数传入普通的Pure function中呢?
这里Haskell引入了Functor的概念:
class Functor f where
fmap :: (a->b) -> f a -> f b
他将一个普通的函数(a -> b)提升为对包装类进行操作的Functor (f a -> f b)。这里f是包装函数。这样使得任何包装类型都可以轻松继承所有pure function的代码。在Monad中定义了这样的一个提升操作,称之为liftM
liftM :: (Monad m) => (a -> b) -> m a -> m b liftM f m = m >>= \i -> return (f i)
这样任何一个f都可以对Monad中包装的值通过“提升操作”进行调用了。这里的liftM仅针对单参函数(a -> b)。我们的MovieReview需要3个参数,这里我们可以借用haskell函数库中的liftM3,针对3参数函数进行提升。
liftM3 :: (Monad m) => (a -> b -> c -> d) -> m a -> m b -> m c -> m d
liftM3 f m1 m2 m3 =
m1 >>= \a ->
m2 >>= \b ->
m3 >>= \c ->
return (f a b c)
那我们的代码又可以进一步简化了
liftReview alist =
liftM3 MovieReview (lookup "title" alist)
(lookup "user" alist)
(lookup "review" alist)
看,经过提升之后MovieReview就像是可以接受三个Maybe作为参数一样地进行调用了,并且>>=符隐藏在了liftM3中,其中控制了一旦任意一个maybe为nothing的时候短路这个流程。虽然这样client代码已经非常优美了,但是lib代码会有些问题。这里的liftM3已经有些呆板了。如果是要提升10个参数的函数怎么办。精益求精,Haskell提供了ap函数让提升操作可以链状调用。
ap :: (Monad m) => m (a -> b) -> m a -> m b ap = liftM2 id
从函数类型可以看出,他要求将pure function (a -> b)包装到monad中。这样做可以进行链式调用。可是为何通过这样的链式调用就能将多参函数链式提升了呢?这是因为实际上haskell仅支持单参函数。例如(a -> b -> c -> d)这个类型,他表示接受(a, b, c)三个参数,并且返回d类型的函数。这个函数实际上是接受a类型的参数,并且返回一个(b-> c -> d)类型的函数的函数。这有点像是通过接受了参数a来绑定了三个参数中的一个,生成了一个偏特化的函数(partial function)。
ap函数类似是通过提升将这个多参函数的第一个参数提升了,返回用monad包装的偏特化函数(m b)。这个新的被monad包装的函数可以继续传入ap,继续偏特化下一个参数。因此这个操作可以链式提升多参函数的每一个参数,最终完成提升过程。这里ap的名字意思是“apply”,就能清楚他的意义了。
ap实际上通过liftM2 id实现。id是返回本身
id a = a
而liftM2提升两个参数并返回调用f的包装结果,现在f是id
liftM2 :: (Monad m) => (a1 -> a2 -> r) -> m a1 -> m a2 -> m r
liftM2 f m1 m2 =
m1 >>= \a1 ->
m2 >>= \a2 ->
return (f a1 a2)
liftM2 id =
m1 >>= \a1 ->
m2 >>= \a2 ->
return (a1 a2) -- id means self
这里有个不太符合直觉的地方,return (a1 a2)就是m (a1 a2), 他怎么就变成ap的m (a -> b) -> m a -> m b了?
这要看传入的参数。ap接受两个参数分别是m (a -> b)和 m a。用这两个参数替换liftM2的a1和a2后
liftM2 id (m (a -> b)) (m a) =
m (a -> b) >>= \(a -> b) ->
m a >>= \a ->
return ( (a -> b) a)
经过这个推导,可以清晰地看出,liftM2 id将ap的第一个参数m (a -> b)提升后绑定了第一个参数a,也就是ap的第二个参数m a。并且返回了绑定参数后的偏特化函数b的包装monad, m b。这个绑定的过程可以在最后一句体现出来:return ( ( a -> b ) a)。对(a->b)应用参数a。
从这里可以看出monad是一个极端抽象的概念,讨论他经常会遇到不易理解的地方,只有带上实际使用的参数后才能容易理解。
利用ap函数的代码如下,这里使用`符号包裹一个双参数的函数,将函数当作操作符来使用,从而得到链式调用的代码
liftReview alist =
MovieReview `liftM` lookup "title" alist
`ap` lookup "user" alist
`ap` lookup "review" alist
好了,做个小结。我刚学haskell不久,对monad有了一个初步的了解。可以看到monad是一个实践性非常强的抽象,涉及到的lift, functor等概念,如果只是形式上地看他的设计,很难理解设计的意图,就像是一坨抽象废话。但是一旦从实践中多利用这些工具,就能轻松的避免各种各样的代码坏味,得到美观自然和可读性非常强的代码。Haskell这样的语言,只要用心设计好函数和变量名,即使不写注释也能明白代码的意图,并且很难出错。因为他把实现隐藏起来,代码就是直接表达了意图。我认为这是非常有潜力的语言,今后会做进一步的学习和研究,并尽快将其用于实战。
换到自己的笔记本上做安卓开发,出现了一个很烦人的问题,就是一直报
Can't bind to local 86XX for debugger
这样一个错。网上查了一下,原因是jre7不兼容的问题,需要退回到jre6才行。我安装了jre6,又不想卸载jre7,就想,改了环境变量的PATH应该就好了吧。
JAVA_HOME = "C:\Program Files\Java\jre6"
PATH = "...;%JAVA_HOME%\bin"
可是修改之后,进入命令行输入java -version一看,问题没有解决,还是java 1.7的版本。这很奇怪啊。
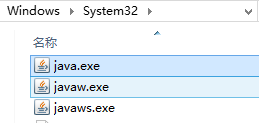
网上继续查了一下,原来java installer会把java.exe复制一份到windows/system32下面,而PATH的特点是先到先得,在系统目录找到java.exe后,就直接执行了。需要把jre\bin的目录在PATH中设置到系统目录之前,就解决问题了。
JAVA_HOME = "C:\Program Files\Java\jre6"
PATH = "%JAVA_HOME%\bin;..."
顺带再骂一句java,每个主要版本升级都闹出一堆不兼容来,不知怎么想的。一处开发到处执行这个口号唉。。。不提。。
又记起那时候在公司配置Jira系统的痛苦了。。
参考
两年前我写了一篇博emacs + cygwin fail,说的是在cygwin中使用emacs的种种不便。这些问题已经得到解决。但如今我的需求又有了转变,想在native emacs on windows上使用cygwin作为shell,于是又产生了新的问题。今天看到ownwaterloo在我博客里的留言,想到应该花点时间把以前遗留下来的问题解决掉,于是有了这篇文章。
在emacs中使用cygwin作为shell,可以使用这个cygwin-shell.el
http://lists.gnu.org/archive/html/help-gnu-emacs/2010-02/msg00668.html
然后在.emacs中如此启用之
(load "D:\\programs\\emacs-24.3\\site-lisp\\cygwin-shell.el")
为了方便可以绑定一个快捷键
(global-set-key (kbd "M-s") 'cygwin-shell)
重启emacs试用,发现不工作,原来是bash的路径需要填对:
(let* ((shell-file-name "D:\\cygwin\\bin\\bash")
再进去看,可以用了,但是提示符乱码。根据网上的一些讨论,打开bash.bashrc查看
# Set a default prompt of: user@host and current_directory
PS1='\[\e]0;\w\a\]\n\[\e[32m\]\u@\h \[\e[33m\]\w\[\e[0m\]\n\$ '
由于我用的emacs版本支持分色显示,我删除了前面的\w\a部分,保留了分色显示的\u@\h部分。
# Set a default prompt of: user@host and current_directory
if [[ $TERM = "emacs" ]]; then
PS1='\[\e[32m\]\u@\h \[\e[33m\]\w\[\e[0m\]\n\$ '
else
PS1='\[\e]0;\w\a\]\n\[\e[32m\]\u@\h \[\e[33m\]\w\[\e[0m\]\n\$ '
fi
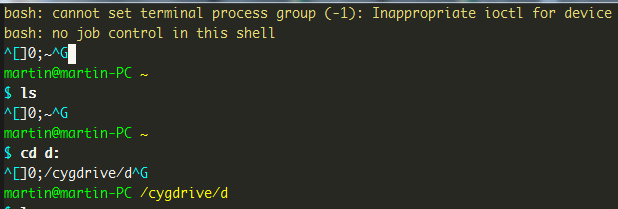
还有一个问题,就是登录进去后显示两行错误:
bash: cannot set terminal process group (-1): Inappropriate ioctl for device bash: no job control in this shell
这是说emacs没有提供TTY给bash,因此bash拒绝提供job control功能,也就是说C-c强关进程、&后台执行、C-z挂起等命令行功能都不能使用,非常不便。其实我一般不太用到这些功能,偶尔用到就用emacs的多窗口开多个窗口来执行不同的命令,很长时间就没有去管他。今天由于跟ownwaterloo邮件提到,就想试试解决一下。根据网上的说法,这是个没有解的BUG。。
不过这个问题是从cygwin 1.7.10之后才出现的,可以找到许多帖子在升级到1.7.10~1.7.11过程中抱怨这个事情
既然如此,就不去费心琢磨怎样能给cygwin一个TTY环境了。只好根据人家提供的两条解决方案想想看怎样去找到旧版本的cygwin。
Workarounds: * Use Cygwin Emacs (package emacs-w32 uses the windows GUI, there are also X11 and console packages) * Don’t upgrade Cygwin above, I think Cygwin1.dll, version 1.7.9.
由于cygwin官网并不提供旧版本的cygwin安装,只好去找旧版本的镜像。我尝试了许多关键词,搜了一下午,踏遍无数国外的垃圾下载站,被各种坑骗之后,终于在一个必须注册才能下载的网站找到了可以安装的1.7.9版本,号称最后一个兼容emacs的cygwin版本的下载
http://search.4shared.com/postDownload/lMzinjJj/cygwin_179-1.html

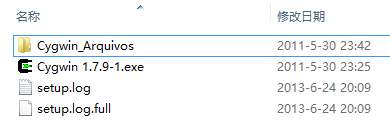
直接将1.7.9的cygwin1.dll拷贝到bin目录是不可行的,我下载并尝试过,bash可以执行,但是一些命令,如ls和svn执行没有输出。奇怪的是其他的程序如grep和git又可以执行,可能只是几个函数的挂接点有变化了吧。因此必须重新安装一遍cygwin。方法是启动旧版本的setup.exe后,选择“Install from Local Directory”,并在后续步骤中的“Local Package Directory”选择下载文件附带的那个路径“Cygwin_Arquivos”(我查了一下这似乎是葡萄牙语的Archive的意思,感谢这位葡语程序员!)
完成安装后,一种方案是可以将cygwin-shell.el中的bash路径指向新装好的cygwin路径,我没有采用。由于我已经在原有的cygwin 1.7.20版本中安装了不少应用,不想切换目录了,因此我尝试将1.7.9的bin目录覆盖到1.7.20中去。居然成功了![其实失败了…]
这次在emacs中测试,正确启动,一切命令正常!有趣的是,用cygcheck -c cygwin检测,查出来的版本还是1.7.20版本。而且新版的mintty.exe也可以正确的使用。非常开心~这暂时可以算是完美解决了~
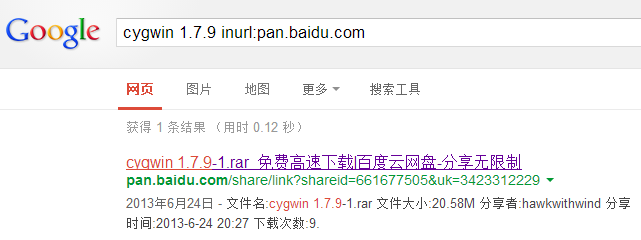
假如有其他人恰好有跟我一样的蛋疼需求,想在windows native emacs中启用cygwin,又不堪各种坑查到我的博客,为了方便这样的小众同好,我这里给一个百度网盘的link吧。说实话百度开放网盘内容搜索还算挺有用的(虽然总感觉挺可怕的。。),我曾幻想在google中 site:pan.baidu.com 搜索cygwin 1.7.9就能搜到程序包,可惜失败了。这次我提供公开下载,未来再这样搜索的人就能得到方便了吧!
[cygwin 1.7.9 本地安装包] http://pan.baidu.com/share/link?shareid=661677505&uk=3423312229
后注
- 事实上直接将1.7.9 bin目录中的内容覆盖到1.7.20中是不行的,部分程序无法执行。还是需要老老实实将脚本中的bash路径指向1.7.9版本。
- 现在在Google中搜索cygwin 1.7.9 inurl:pan.baidu.com会直接找到这个资源了,只有一个搜索结果,就是我的链接,哈哈
本文引用的图片和部分讨论来自网上,以下是主要参考来源的整理
中午跟基友讨论的三门问题,我一直坚持“1/2”观点还写了很长的博客去分析。
掷骰子的上帝-冷眼看三门问题
到了傍晚,终于被基友说通了,恍然大悟自己的错误。。立刻补博客谢罪。。
基友是个不擅言辞的人,言语上一直没有说出能说服我的道理。但是他的一句话忽然点醒我,说让我写程序试试。虽然我认为写程序测试没有必要,但尝试从程序的角度思考的话,的确,一开始就选定一扇门,并且无论看到什么都坚持不换,那测试100次,这样选中的概率,跟3选1选中的概率当然是没有区别的。只能是1/3。那么跟这个策略相反的,坚持换选另一扇门的策略,一定能把剩下2/3的情况都吃光。
如果这点不够显然的话,可以假设有兄弟二人一起去参与这个活动,每次都是弟弟坚持不换哥哥坚持换。这俩人一定能包揽所有的汽车,并且弟弟获得汽车的概率肯定是1/3,跟3选1的概率相同。则推出哥哥选到汽车的概率应当是2/3。
我尝试用一个比较显然的方法说服自己,感觉应该是这样。一开始选择了一扇门,这个动作本身将三扇门分为了两份,“我选择了的门”和“我没有选择的门”。主持人在你没有选择的门里面开一扇,说这扇后面是羊。然后问你,你选“我选择了的门”,还是选“我没有选择的门”里面,除了打开不是羊的那扇门之外,剩下的一扇。
如果这样说还不够明白,进一步构造的话。一开始选择了一扇门,这个动作本身将三扇门分为了两份,“我选择了的门”和“我没有选择的门”。主持人不开任何门,直接问你,你选“我选择了的门”还是“我没有选择的门”。一个只有一扇门,一个有两扇门,当然选“我没有选择的门”啦!重新选择了“我没有选择的门”之后,主持人再从那里面找一个是羊的门,打开。这个情况跟先打开再换选,实际是完全等价的。因此换选这个策略能达到2/3的概率,就显而易见了,一个是选了一扇门,一个是选了两扇嘛。
呜,之前的博客中还有对“果壳死理性小组”不屑言论,深表惭愧及歉意。特保持原博客原状,作为对自己错误的惩罚。
本篇博客观点是错的,我已补新篇谢罪。特保留本篇文章原状作为自我惩罚和警示。
今天基友硬拉着我跟我争论了一个经典的概率问题:三门问题。
问题是说,在机智问答的最后抽奖环节,有三扇门,其中两扇门背后是山羊,一扇门背后是汽车。一旦你选择了一扇,主持人就会选择你没选中的那扇并且打开它。当然这后面一定是山羊啦。这时候你换选另一扇还是保持原来的选择?
这个问题我很早之前就看过,我没多想。再选的概率一定是1/2我认为这没什么可讨论的。但是基友一定要跟我争,而且有一套挺不错的逻辑。我一时说不出他的逻辑有什么错。争论结束我回来还是余兴未央,搜索了一个帖子,是讲这个问题的
换还是不换?争议从未停止过的三门问题~
我努力抛弃原有的想法,尝试理解这种观点。认为换比不换好的人,思路是这样的:
1) 我选了一扇门,后面是羊还是车我不知道,但是是羊的概率是2/3,是车的概率是1/3。
2) 主持人开了一扇门,门后必然是羊;
3) 如果我选的门后是羊,剩下的一扇门背后必然是车;概率2/3
4) 如果我选的门后是车,剩下的门背后必然是羊;概率1/3
这个思路看似缜密实则混淆了概率的基数。
1)和 2)两点都是无可争议的。
我们看第3)点。如果我选的是羊,换门就是车,这也没问题。但问题是,现在我选的是羊的概率还是2/3吗?
当三扇门都未打开时,我选一扇门,门后是羊的概率是2/3,这是没有问题的。但要仔细考虑,为什么是2/3?这个概率是谁贡献的?
不妨设门后的三个物件为:羊A,羊B,车C。
我选一扇门,门后有这三物件任意一件的概率都是1/3,是羊的概率是2/3其实是羊A的概率 1/3 加上 羊B的概率1/3。
当主持人打开一扇门,露出了一头羊,不妨说是羊B吧。这个时候其实你选择到是羊B的概率就是0了!你不可能选择了羊B。
所以可能性只有你选择了羊A,和你选择了车C。所以你选羊A的概率是1/3,选车C的概率也是1/3。你换门得到车的概率是1/3,不换门得到车的概率也是1/3。是一样的。这样说有点不太对,因为是羊B的那1/3的概率已经不可能存在了。整体系统的概率是1。所以说的概率1/3其实是主持人开门之前的概率了,主持人开门观测一扇门后的物件这个动作,其实影响了整个系统的概率。他开的这扇门确定是羊,就说是羊B好了。那么是羊B的概率就是100%,是羊A的概率就是0,是车C的概率也是0。所以剩下两扇门,无论你选了哪一扇,是车的概率都是1/2,是羊的概率也都是1/2。
| 观测前 | 门1(羊A 1/3,羊B 1/3,车C 1/3) | 门2(羊A 1/3,羊B 1/3,车C 1/3) | 门3(羊A 1/3,羊B 1/3,车C 1/3) |
|---|---|---|---|
| 观测后 | 门1(羊A 1/2,羊B 0, 车C 1/2) | 门2(羊A 1/2,羊B 0, 车C 1/2) | 门3(羊A 0, 羊B 1, 车C 0 ) |
有人争论说,主持人是上帝,是知道每一扇门后面是什么的,所以他刻意开一扇门的动作,会影响与之相关的孤立事件的概率。让某一扇门变得特殊。但是,这是一个掷骰子的上帝,不是一个决定性的上帝。因为他能知道的只是一扇门后是羊还是车,却不能决定你选的那扇门背后是羊还是车。更进一步的,他只能在你选了羊A的时候打开羊B的门,你选了羊B的时候打开羊A的门。这个“上帝”的选择,其实受控制的。受一开始你选了哪扇门这个“骰子”的控制。所以我说他是一个掷骰子的上帝。这就像是量子理论里面的“量子纠缠态”,当你观测一组纠缠态粒子中一个粒子的状态时,整个系统的状态都被破坏了。
从这个角度重新看这个问题,你选择了一扇门,的确,这个时候门后是羊的概率是2/3。但是主持人打开了另外一扇门,观测结果是羊B。这个观测结果,让你选择的那扇门背后是什么物件这个问题的“量子叠加状态”坍缩了,从原来可能是羊A(1/3)、羊B(1/3)、车C(1/3),坍缩到了羊A(1/2)、车C(1/2)。你会说,凭什么他开门观测到的是羊B,还可能是羊A呢?是的那个可能已经处于另一个平行宇宙了。在一开始你掷骰子选门的时候就决定了(如果你选的是车C,那么这个骰子在主持人决定开门的时候还会再掷一次,这里是有些不同,因为车与羊的不同引起)。
我们回到这个问题的初始,为什么会产生这样的争论呢?其实这不是概率学的争论。任何有点概率常识的人都会算这个概率。其实这是主观与客观之争。
假如你不是参与选择的玩家,而是客观的站在一旁看着。原来有三扇门,每扇门后面是车的概率都是1/3。现在有一扇门是透明的,能清楚看到门后面是一头羊。那么另外两扇门后是车的概率都是1/2。这是无可争议的。
一旦你参与了选择,将其中一扇门特别设定为“我选择了的门”,将其他门设定为“我没有选择的门”,这个时候问题才会产生,以至于“果壳死理性派”都会产生这么多不“理性”的言论。归根结底是人的主观性所致。一旦有了立场,客观的东西就似乎是错的了。这是人类的一大困境。
与此相关的还有量子力学中双缝干涉实验中著名的“观测者悖论”,认为观测结果似乎有可能反过来影响实验过程。这当然是不可能的。就像这个三门问题,难道是主持人打开了一扇门,出现了羊B,才影响了你选择的门背后是羊的概率从2/3坍缩到1/2的吗?其实不是。事实是既然这个游戏规则是一定会刨除一扇背后有羊的选项,事实上你选到车的概率从一开始就是1/2,从来就没改变过。甚至于,主持人开门出现的是羊A还是羊B,很大程度都是你自己的选择决定的:当你选择羊A的门,他只能打开羊B的门;反之亦然。只有你选择车C的门,才稍稍留了一点不确定性。
由于人存在于时间的流动之中,才会对因果律过于执着,对主观的选择和选择的结果过分的看重。所以马塞尔说,“人是时间性的存在”。如果冷眼看之,其实选与不选,本来都是选择,又都相当于没有选择。宇宙运行无非是掷骰子的上帝玩弄着的复杂机械罢了。
今天碰巧朋友问到我怎么识别独立的安卓手机,就花了一些时间琢磨了一下。
其实这个问题可以秒答,就是IMEI。
TelephonyManager.getDeviceId();
这需要一个权限:
<uses-permission android:name="android.permission.READ_PHONE_STATE" />
问题如果这么简单就好了,问题在于:
因此其实问题从这里才开始。网上能够搜索到的解决方案有以下几点:
一个方案是优先采用IMEI,当IMEI相同时,再比较WIFI的MAC地址。但如果手机没有WIFI功能或者WIFI功能没有开启(飞行模式),则无法获取到MAC地址。更加让人惆怅的是,我国大山寨厂商实在是懒透了,无线网卡的MAC地址居然也不修改,不少自刷机的也是这病情(例如这个,这个还有这个)。至于说蓝牙MAC地址就更别说了。IMEI重复的病因,与MAC地址相同的其实是一个原因,都是刷机或山寨,所以这个wifi MAC地址的方案其实算不上互补了,必须另谋途径。
另一个方案是用serial NO。这个值仅在android 2.3版本以上才提供支持。通过adb可以这样查看:
adb shell getprop ro.serialno
代码中可使用系统变量android.os.Build.SERIAL访问。如果这个值能够取到这是仅次于IMEI的最好方法了。缺点是这个值在2.2及以下版本的android系统不支持。不过好在如今的安卓世界2.2及以下的占有率已经越来越低了,翻新速度很快,因此这个值很值得一试。
其实安卓系统提供了Settings.Secure.ANDROID_ID来获取唯一设备号。
import android.provider.Settings.Secure;
private String android_id = Secure.getString(
getContext().getContentResolver(),
Secure.ANDROID_ID);
但同样2.2以前的系统支持得不好。这个值是系统初次启动后生成的,因此恢复出厂设置后这个值会变,导致观测到的设备数虚高。在手机刷机、重置频繁的环境,这个值是不靠谱的。另外某大厂生产的设备居然有个BUG,这个值是会重复的(DROID2),因此这个值还是别用为好。
最后还有一个自己生成UUID的办法,保存这个ID,每次访问服务器时上传,自己告诉系统自己是谁。这个方法比所有硬件方法都更不靠谱,因为只需卸载软件和清理数据就会导致这个值被删除,从而产生新的UUID,造成观测到的设备数量虚高。更别说刷机和恢复出厂设置了。这个方法非常适合用来统计软件安装次数,而非独立设备数。
综上所述,目前为止我还没找到非常完美的统计独立设备的方案,尤其是在中国这个水货、硬解、山寨、刷机市场泛滥和不规范的安卓世界,更是难上加难。
但是反过来想,是不是一台完全刷新,安装了全新的ROM的手机,就已经不是原来的那台手机了呢?统计独立设备数的目的究竟是什么?如果要的是独立活跃设备数,其实用自己生成的UUID已经足够,因为原来使用的那个UUID已经失去活性,可以忽略了。对于APP开发者而言这个情况与用户换了一台手机,完全弃用旧手机的情况其实是一样的。假如是采取活跃UUID的方式,则即使是使用ANDROID_ID或者自己生成的UUID都是可取的做法了。
荒废好久的博客。。俺回来鸟。
又是出差北京,体验北方冬天的干冷。
在出租车上堵得无聊,就跟师傅闲扯。我很呆地问:“这五环上又没有红绿灯十字路口,所有的车都往前开,照理说车再多也不可能堵车啊。”
师傅回答:“人多事儿多呗。抽口烟,喝口水,旁边撞车了踩脚刹车看看撞得咋样儿。可不就堵了么。”
“哦。”
原来高速路上也能堵车,是这么个理儿。
果然磨磨蹭蹭挪了20多分钟,前面有个撞车的。过了那辆车,前面一大段路都是一路畅通了。真的很有意思,因为没有岔路,主干线上仅仅一处事故就能引发整条高速路的拥堵。由于人多车多,这偌大的五环上只要有那么三五处事故,就能全天二十四小时不间断堵车了。
如果真是这么有趣的原因导致堵车,那么解决方案似乎也很简单啊。最极端的方案就是全面实施自动驾驶。上高速路不算,进了路,速度平稳之后,必须切换到自动驾驶。这自动驾驶首先不会出事故,更不会因为旁边有事故现场就减速看热闹。这么一来五环的运力就可以用一个简单公式计算:车速×车道 / 车距。根本不可能堵车嘛。
当然短期内还不可能全面实施自动驾驶,那么稍微简单点的办法就是通过广大司机们的自觉。说劣根性那是没办法,但矫正总还是有机会的。哪个北京司机不骂北京交通的,哪个司机不想早那么一点到目的地的。如果大家都知道,就因为自己多踩一脚刹车,晚起步半秒,导致的蝴蝶效应正好绕五环一周,叠加在自己的堵车时间上,那么为了快每个人在五环上就更冷血点,更严肃点,更快更少小动作点,事情不就解决了嘛。
这跟市内交通还不一样。毕竟在五环上,没有十字路口没有红绿灯,大家都往一个方向走,并且除了特别的时间段,通常来讲上五环和下五环的车数是相等的(除非有车想赖在五环上就不下来了)。所以只要大家都快起来,五环自然就不会再堵了。
另外可以提建议的,就是不如砸点钱搞几架直升飞机支持高速路上的事故处理。你派拖车过去把事故车再运走,一天时间都没了,可能保险公司来调查的人还堵在半路呢。直接直升飞机把该来的各方面人员都带过来,一股脑解决,把事故车吊走,至少吊离现场把,运到附近公路上再慢慢等拖车呗,能解决多少运力问题。那烧在路上的时间,分分钟都是钱啊,光节约的油钱就够多少架直升机了。