两年前我写了一篇博emacs + cygwin fail,说的是在cygwin中使用emacs的种种不便。这些问题已经得到解决。但如今我的需求又有了转变,想在native emacs on windows上使用cygwin作为shell,于是又产生了新的问题。今天看到ownwaterloo在我博客里的留言,想到应该花点时间把以前遗留下来的问题解决掉,于是有了这篇文章。
在emacs中使用cygwin作为shell,可以使用这个cygwin-shell.el
http://lists.gnu.org/archive/html/help-gnu-emacs/2010-02/msg00668.html
然后在.emacs中如此启用之
(load "D:\\programs\\emacs-24.3\\site-lisp\\cygwin-shell.el")
为了方便可以绑定一个快捷键
(global-set-key (kbd "M-s") 'cygwin-shell)
重启emacs试用,发现不工作,原来是bash的路径需要填对:
(let* ((shell-file-name "D:\\cygwin\\bin\\bash")
再进去看,可以用了,但是提示符乱码。根据网上的一些讨论,打开bash.bashrc查看
# Set a default prompt of: user@host and current_directory
PS1='\[\e]0;\w\a\]\n\[\e[32m\]\u@\h \[\e[33m\]\w\[\e[0m\]\n\$ '
由于我用的emacs版本支持分色显示,我删除了前面的\w\a部分,保留了分色显示的\u@\h部分。
# Set a default prompt of: user@host and current_directory
if [[ $TERM = "emacs" ]]; then
PS1='\[\e[32m\]\u@\h \[\e[33m\]\w\[\e[0m\]\n\$ '
else
PS1='\[\e]0;\w\a\]\n\[\e[32m\]\u@\h \[\e[33m\]\w\[\e[0m\]\n\$ '
fi
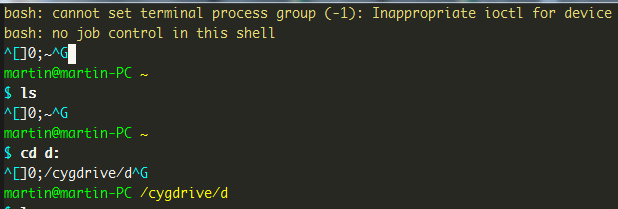
还有一个问题,就是登录进去后显示两行错误:
bash: cannot set terminal process group (-1): Inappropriate ioctl for device bash: no job control in this shell
这是说emacs没有提供TTY给bash,因此bash拒绝提供job control功能,也就是说C-c强关进程、&后台执行、C-z挂起等命令行功能都不能使用,非常不便。其实我一般不太用到这些功能,偶尔用到就用emacs的多窗口开多个窗口来执行不同的命令,很长时间就没有去管他。今天由于跟ownwaterloo邮件提到,就想试试解决一下。根据网上的说法,这是个没有解的BUG。。
不过这个问题是从cygwin 1.7.10之后才出现的,可以找到许多帖子在升级到1.7.10~1.7.11过程中抱怨这个事情
- bash under emacs gives “cannot set terminal process group”
- “Inappropriate ioctl for device” problem using latest cygwin as a shell within native (non-cygwin) GnuEmac
既然如此,就不去费心琢磨怎样能给cygwin一个TTY环境了。只好根据人家提供的两条解决方案想想看怎样去找到旧版本的cygwin。
Workarounds: * Use Cygwin Emacs (package emacs-w32 uses the windows GUI, there are also X11 and console packages) * Don’t upgrade Cygwin above, I think Cygwin1.dll, version 1.7.9.
由于cygwin官网并不提供旧版本的cygwin安装,只好去找旧版本的镜像。我尝试了许多关键词,搜了一下午,踏遍无数国外的垃圾下载站,被各种坑骗之后,终于在一个必须注册才能下载的网站找到了可以安装的1.7.9版本,号称最后一个兼容emacs的cygwin版本的下载
http://search.4shared.com/postDownload/lMzinjJj/cygwin_179-1.html

直接将1.7.9的cygwin1.dll拷贝到bin目录是不可行的,我下载并尝试过,bash可以执行,但是一些命令,如ls和svn执行没有输出。奇怪的是其他的程序如grep和git又可以执行,可能只是几个函数的挂接点有变化了吧。因此必须重新安装一遍cygwin。方法是启动旧版本的setup.exe后,选择“Install from Local Directory”,并在后续步骤中的“Local Package Directory”选择下载文件附带的那个路径“Cygwin_Arquivos”(我查了一下这似乎是葡萄牙语的Archive的意思,感谢这位葡语程序员!)
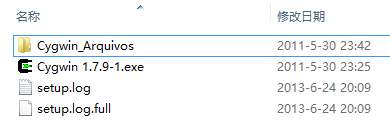
完成安装后,一种方案是可以将cygwin-shell.el中的bash路径指向新装好的cygwin路径,我没有采用。由于我已经在原有的cygwin 1.7.20版本中安装了不少应用,不想切换目录了,因此我尝试将1.7.9的bin目录覆盖到1.7.20中去。居然成功了![其实失败了…]
这次在emacs中测试,正确启动,一切命令正常!有趣的是,用cygcheck -c cygwin检测,查出来的版本还是1.7.20版本。而且新版的mintty.exe也可以正确的使用。非常开心~这暂时可以算是完美解决了~
假如有其他人恰好有跟我一样的蛋疼需求,想在windows native emacs中启用cygwin,又不堪各种坑查到我的博客,为了方便这样的小众同好,我这里给一个百度网盘的link吧。说实话百度开放网盘内容搜索还算挺有用的(虽然总感觉挺可怕的。。),我曾幻想在google中 site:pan.baidu.com 搜索cygwin 1.7.9就能搜到程序包,可惜失败了。这次我提供公开下载,未来再这样搜索的人就能得到方便了吧!
[cygwin 1.7.9 本地安装包] http://pan.baidu.com/share/link?shareid=661677505&uk=3423312229
后注
- 事实上直接将1.7.9 bin目录中的内容覆盖到1.7.20中是不行的,部分程序无法执行。还是需要老老实实将脚本中的bash路径指向1.7.9版本。
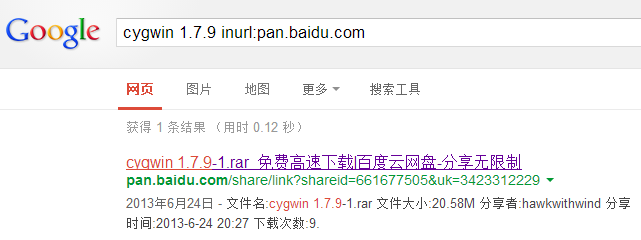
- 现在在Google中搜索cygwin 1.7.9 inurl:pan.baidu.com会直接找到这个资源了,只有一个搜索结果,就是我的链接,哈哈
本文引用的图片和部分讨论来自网上,以下是主要参考来源的整理
本文参考
- [1] How can I run Cygwin Bash Shell from within Emacs?
- [2] I want to run the cygwin bash shell from native windows emacs app
- [3] NTEmacsWithCygwin
- [4] emacs cygwin shell
- [5] help-gnu-emacs: emacs cygwin shell
- [6] cygwin shell in Emacs – output messed up?
- [7] cygwin bash does not display correctly in emacs shell
- [8] cnet download: 1.7.9 is the last version play well with emacs